Unicode
Unicode is one of the encoding standards that encode characters to bytes. Examples of other encoding standards: ASCII, Latin-1(“ISO-8859-1”) etc. Unicode is a superset of all the other character sets. Unicode 1.0 was limited to 65,536 code points (the last code point was U+FFFF), the range U+0000—U+FFFF called Basic Multilingual Plane. In 6.0, Unicode has 1,114,112 code points (the last code point is U+10FFFF).
The ASCII table has a well-defined unsigned int to char mapping from 0 to 127(using 7 bits to represent), but for numbers from 128 to 255, different mappings exist. That calls for a more unified, consistent and clear rule.
As a result, Unicode comes in the stage, which defines a universal intermediate representation in the form of abstract numbers called code points. That means, each character that has a semantic meaning will have a code point(a number) defined in unicode, then each code point can have a variety of ways and various default numbers of bits per character(code units) depending on context. To encode code points higher than the length of the code unit, such as above 256 for 8-bit units, the solution was to implement variable-width encodings. (This definition is from wikipedia, which will be clearer when looking at a following example of euro)
There are 3 main code units(encoding flavors) for unocode: UTF-8, UTF-16 and UTF-32.
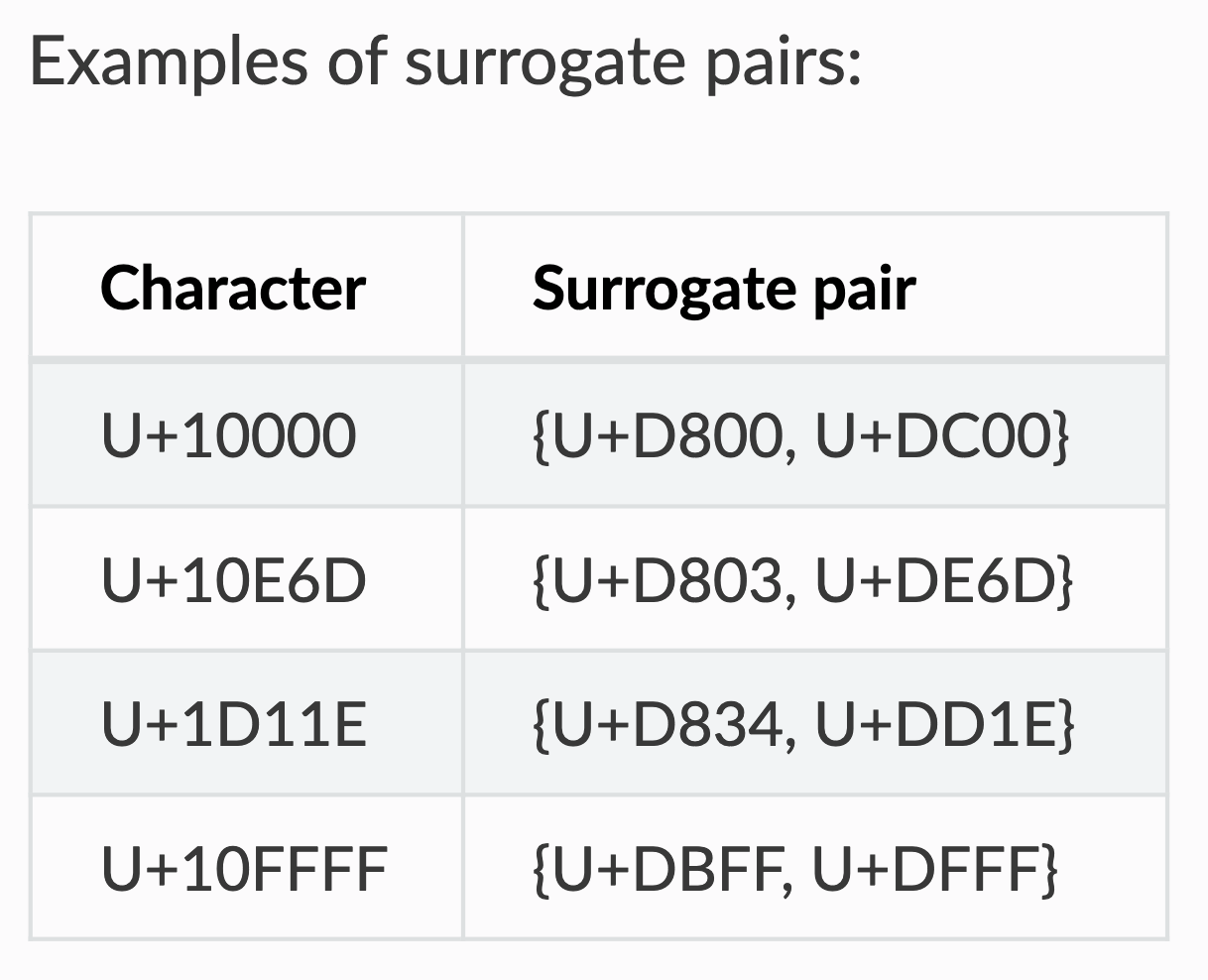
UTF-16 is mainly used in Microsoft Windows and Java/Javascript. It is a variable-length encoding, with code points being encoded with one or two 16-bit code units. In UTF-16, characters in ranges U+0000—U+D7FF and U+E000—U+FFFD are stored as a single 16 bits unit, characters in range U+10000—U+10FFFF are stored as “surrogate pairs” with two 16 bits units: an high surrogate (in range U+D800—U+DBFF) followed by a low surrogate (in range U+DC00—U+DFFF). A lone surrogate character is invalid in UTF-16, surrogate characters are always written as pairs (high followed by low).
UTF-32 is a fixed-length encoding that uses 32 bits per code point, which is rarely used. Both of them are incompatible with ASCII files.
UTF-8 is the most dominant encoding in www, which is a variable length encoding, which uses one byte for the first 128 code points, and up to 4 bytes for other code points. The first 128 unicode code points represent the ASCII chars, which means that any ASCII text is also a UTF-8 text. Code point is just a numerical value that represents a char(for ASCII, each number from 0 to 127 represents a code point). The following table shows the structure of UTF-8 encoding(from wikipedia):

The encoding happens in the following way, taking the encoding of € as an example:
- Unicode code point/coded character is U+20AC
- As this code point lies between U+0800 and U+FFFF, this will take three bytes to encode
- 20AC(hex) = 0010 0000 1010 1100(bin)
- The graph suggests we would use 3 bytes, with the first byte starting 1110, the second & third byte starting 10.
- Encode the first byte: 1110 0010(0010 is the most significant 4 bytes in binary representation)
- Encode the second byte: 1000 0010(000010 is the following bits in binary representation)
- Encode the third byte: 1010 1100(101100 is the following bits in binary representation)
- Final encoding in unicode: 1110 0010 1000 0010 1010 1100(bin) = E2 82 AC(hex). This has 3 code units. For utf-8, one code unit=8 bits, for utf-16, one code unit=16 bits, for utf-32, one code unit=32 bits.
In this example,
- € is a character that has a semantic value of “Euro”
- It is using the Unicode coded character set
- U+20AC is a coded point(which is a valid value in the code space)
- For unicode, the code space is from 0 to 10FFFD
- In different encodings, the code unit is different. Here we are using UTF-8, a code unit in UTF-8 consists of 8 bits.
A case study with ANTLR
For me, the need to understand more about unicode stems from an experience when I was using ANTLR to parse some input. In C++, the line ANTLRInputStream inputStr(s); produces an error: Exception: wstring_convert::from_bytes. Searching in the ANTLR git repo, I find it is this line that errors, which means the utf-8 to utf-32 conversion fails. Combining with the fact that I was seeing a lot of replacement characters when printing out s, which indicates problems when a system encounters some character not conformed to the encoding expectation, I am convinced s is not encoded in utf-8.
Interestingly, from this experience I was also exposed to the concept of wide character(wchar_t in c++, along with wcout, wstring etc), which is a character that is not necessarily in 1 byte, which allows for the use of larger coded character sets.
Source Code Learning: Folly Unicode utf8ToCodePoint
Source code: https://github.com/facebook/folly/blob/master/folly/Unicode.cpp#L52
Comment the code as I read them:
1 | |
References
- UTF-8 Wikipedia
- Character Encoding Wikipedia
- A very nice video tutorial(3 parts are all very good) on ascii, unicode and utf encodings
- The definitions of some terminologies are well explained here
- Unicode encodings