因为一些原因想删除以前发的微博,又想留下记忆看看以前的自己是什么样的,所以想把自己发的微博都保存到本地,然后删除。
python登录微博
一种比较简便的方法是利用cookie登录。先用网页端登录微博后inspect element,找到network下的XHR(XMLHttpRequest),再找到header,能看到cookies。同时找到浏览器的user agent信息。
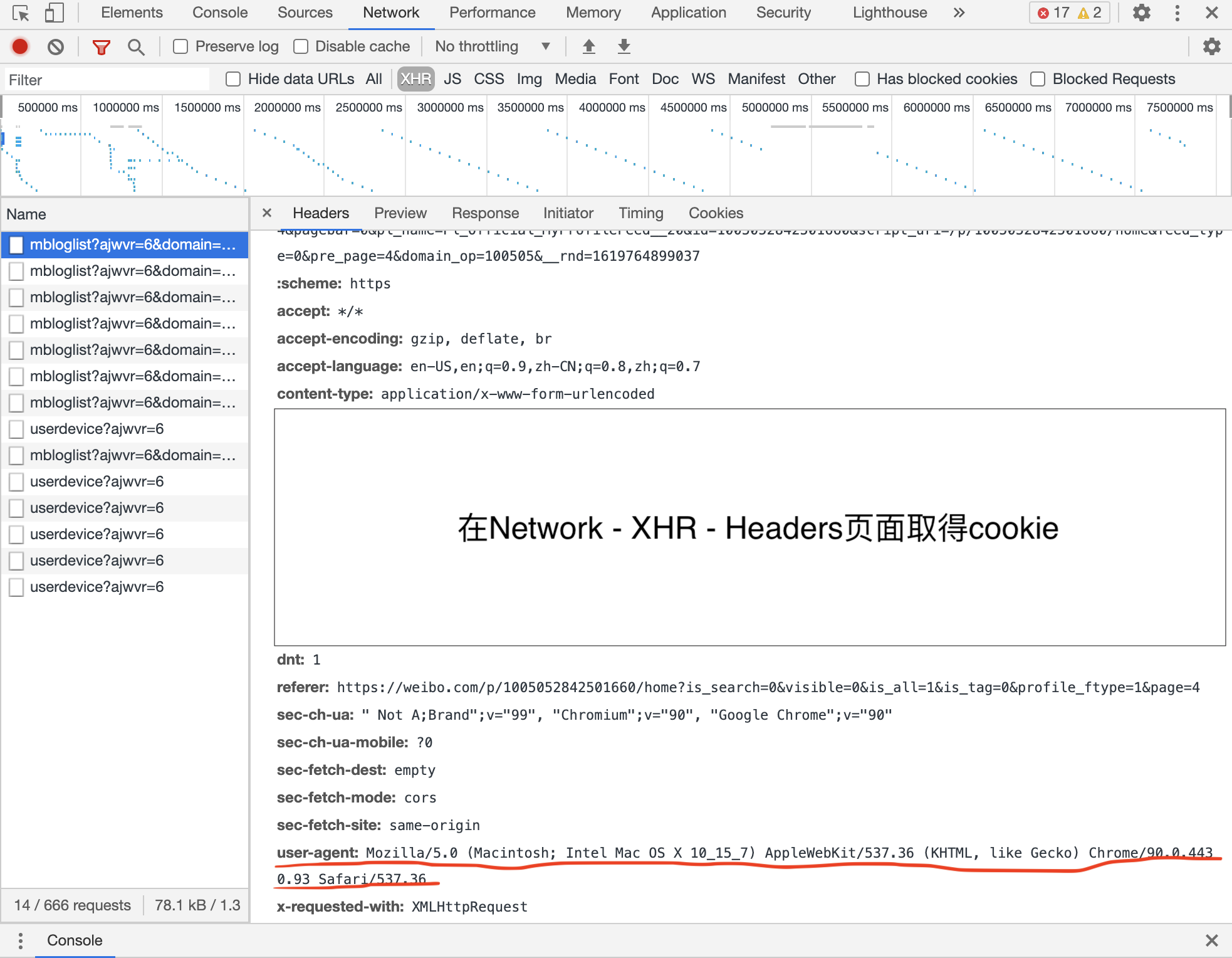
用如下代码实现登录。
1 | |
另一种方法是用post请求登录,稍微复杂一点,我没有尝试,但是网上有相关信息。
找到微博页URL
登录微博并翻到自己的微博第一页的时候发现此时url为https://weibo.com/p/1005052842501660/home?from=page_100505_profile&wvr=6&mod=data&is_all=1。但用这个url有一个问题,此时微博只显示第一页的前15条,需要滚动到页面最下方才能显示另外的微博,一共要重新load两次。找到这些新发的request也很简单,在滚动到下方时再次调出network的xhr页面。
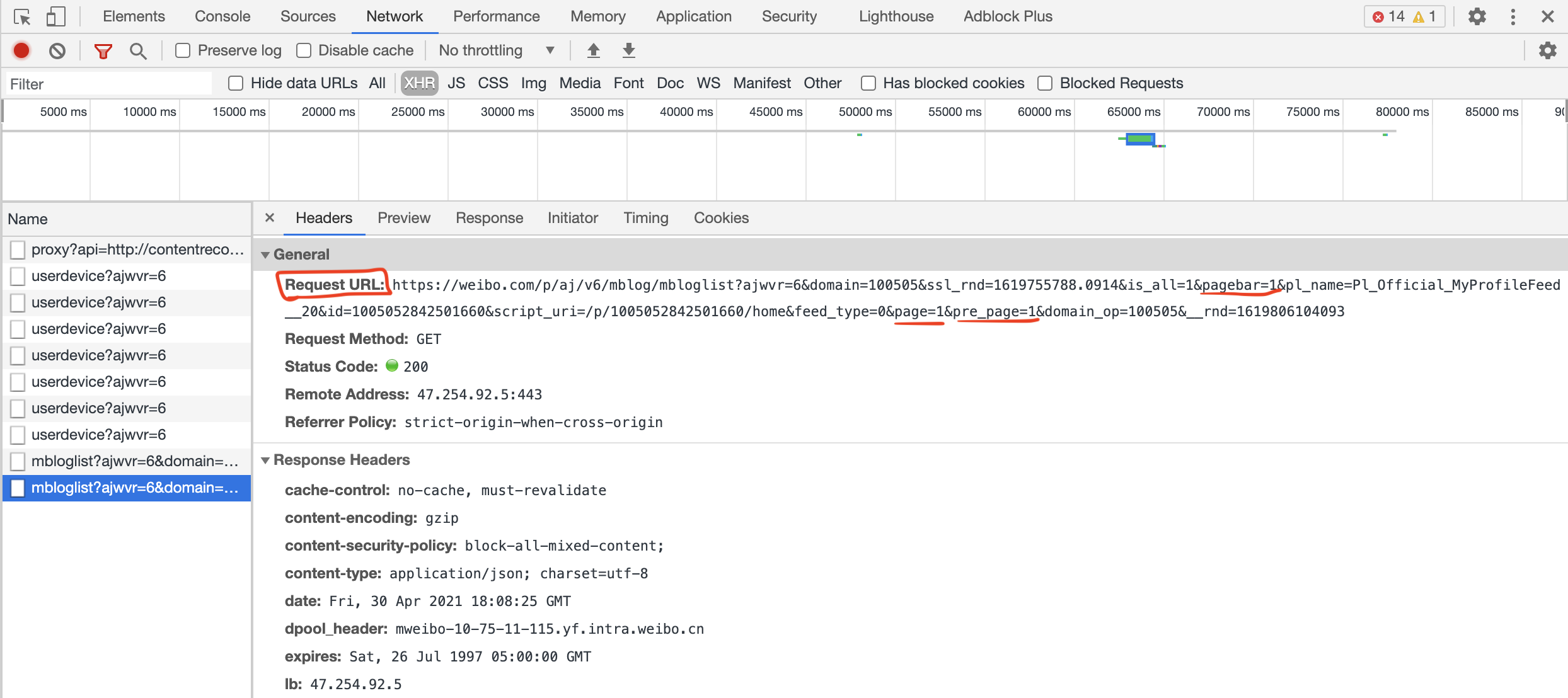
观察url的规律发现,每一页由3组参数组成,分别是
1 | |
也就是说对于一页微博,我们要用以上的参数发三次request。
代码:
1 | |
解析数据
可以print一下拿出来的数据,已经是一个json string了,再用beautiful soup处理一下。观察网页构成发现微博内容的div为<div class="WB_text W_f14" nick-name="XXX" node-type="feed_list_content">。用以下代码实现:
1 | |
解析出来的文字结果就是> 微博内容 这样了。
完整代码
1 | |
删除原微博
把微博保存到本地以后就可以毫无顾虑地删掉原微博啦。在知乎上已经有很多方法了,这里不作赘述。