阅读收获
- 在扩容的每个阶段,有着不同的挑战。对于观察到的瓶颈进行工程上的渐进式优化,了解有什么通用方法,使系统更加稳定高效。
- 理解look aside cache的定义、存在的必要性。了解可能破坏缓存一致性的竞争条件以及应对方法。
Facebook用memcached作为网络服务器和数据库之间的cache层,因为它作为一项开源、成熟的cache技术,很适合公司读远远大于写这样的流量特征,也能支持与不同的后端数据源连接,在某些时候cache中的数据更新延迟可以接受。memcached用内存哈希表储存数据,主要操作有set, get, delete,是一种demand-filled look aside cache。在Facebook的版本中,在读情景cache miss的情境下,由客户端(网络服务器,而非cache层本身)向数据源读取数据,并更新在cache里的数据。在写情景下,网络服务器直接更新数据库,并删除cache层的数据(删除幂等,更好操作)。
在公司流量不断增加的过程中,也经历了几次扩容发展,以下是论文中提到的几个阶段,集中解决的问题以及采用的技术手段。下图为最终架构图。
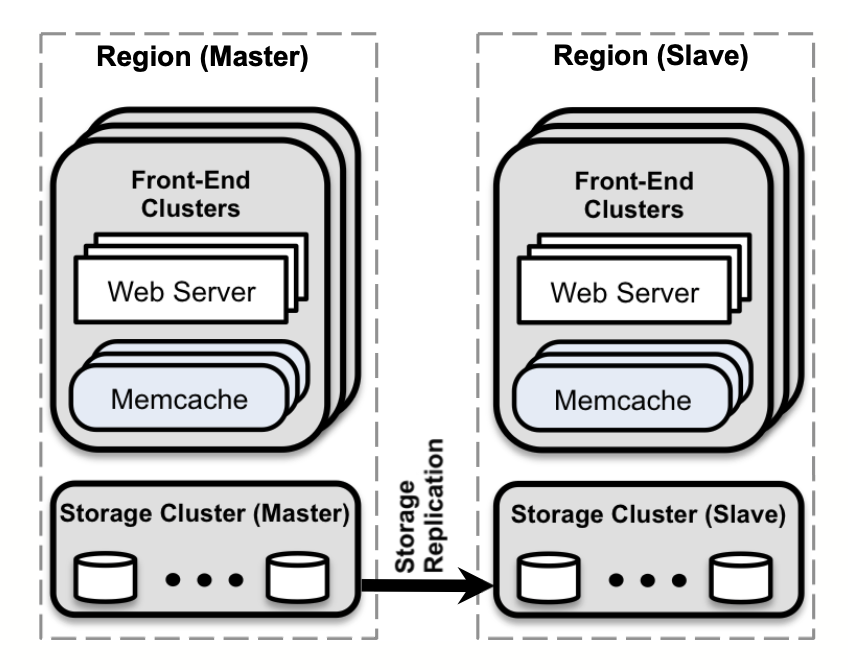
单集群扩容(One cluster in a region)
在这个阶段,由于单机无法满足数据储存和支持大量的读流量,需要增加很多机器。利用一致哈希算法建立数据与机器的映射来避免热点,这也导致了网络服务器可能在一个请求中需要与很多memcached服务器建立连接(all-to-all),进而导致incast congestion(也就是网络服务器端向许多memcached服务器发送了请求,收到回应时可能流量一下太大,这说的是是在客户端也就是网络服务器端的的堵塞而不是memcached端的)。针对这个问题,向TCP滑动窗口机制学习,在网络服务器端设置队列不要一下子向memcached集群发太多请求,在实践中渐渐找到一个不太高也不太低的窗口sweet spot。
为了减少连接数量、增加响应速度,无连接的UDP和面向连接的TCP被混合使用。对于get请求,客户端利用UDP与memcached直连,针对UDP丢包的情况,客户端将其当做请求出错,不会更新memcached中的信息。对于set和delete请求,客户端通过mcrouter中间件与memcached连接。mcrouter承担了连接聚合的作用,减少了客户端与memcached之间的TCP连接。
对于look aside cache来说,可能会出现cache的数据没有及时被更新并与数据源永久不一致的情况:
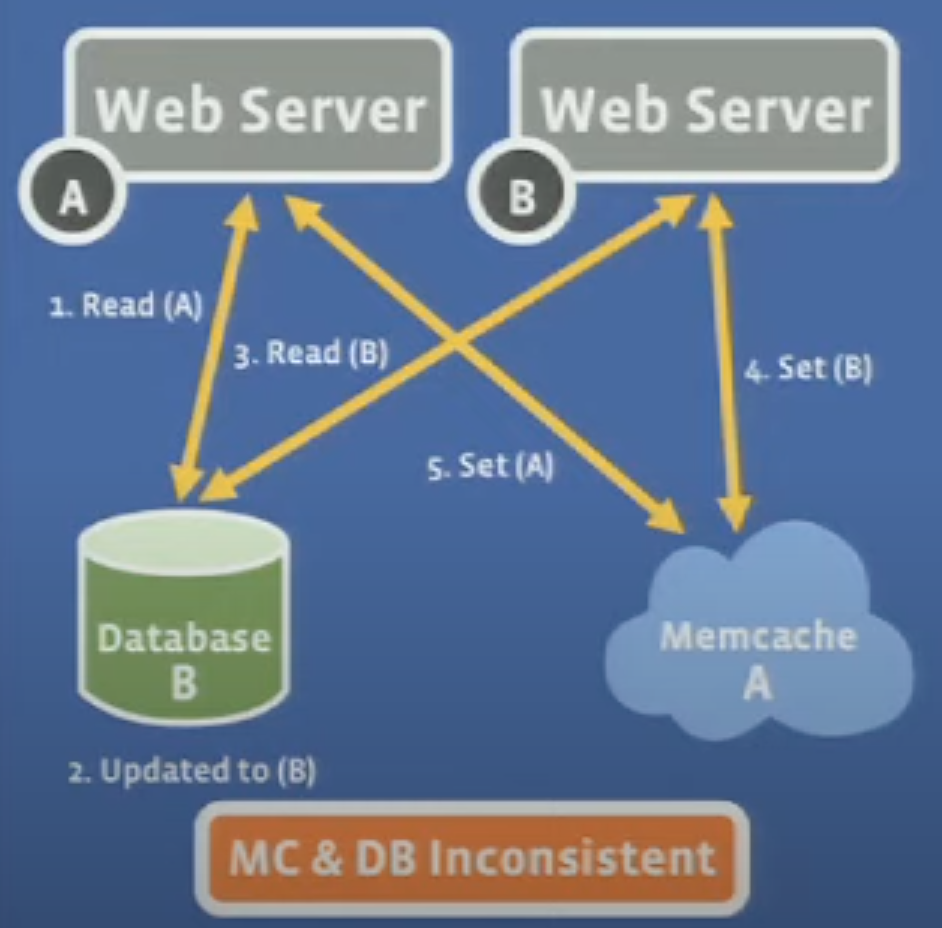
1)客户端A从数据源中读取数据a
2)客户端B更新数据源数据a变为b
3)客户端B从数据源中读取数据b
4)客户端B更新memcache数据为b
5)客户端A更新memcache数据为a
这就出现了memcache与数据源数据不一致的情况。解决这个问题可以在未命中缓存时给客户端一个lease id,在这个例子中,步骤1和3里给了不同的客户端不同的lease id,而步骤2中的“更新数据源”步骤会使得步骤1中的lease id失效,这样就避免了步骤5的情况。
对于look aside cache来说,还可能出现惊群效应(thundering herd)的问题,当缓存缺失时,非常多的客户端可能同时去数据源里找数据,挤爆了数据源。解决这个问题也可以利用lease,当对于同一个token的请求非常频繁时,其中一个带lease的客户端去数据源拿数据并更新memcache里的值,其他客户端被告知等待并重试。
同时,针对不同的流量特征,根据拿数据的频率、重复拿同一份数据的频率、数据大小、缓存缺失时读数据源的成本大小等,设置了几个不同的memcache池,每个池存放不同类型的数据给不同流量使用。在同一个池中,如果经常收到需要同时拿许多key的请求,并且请求频繁、而这些数据能在一个memcached机器中存放时,用数据复制的形式,增加吞吐量。也就是说,我们在多个memcached机器中存放一模一样的数据,当客户请求数据时,可以路由到其中任一机器。选择这么做而不是分割缓存的key space(每台机器存一部分的缓存key)是因为这样的吞吐量会更高。
同区域多集群扩容(Multiple clusters in a region)
一个区域的集群由多个前端集群(一些网络和缓存服务器)和存储集群组成。设置多个前端集群是因为,无限制地扩容前端会带来一些问题,比如加剧incast congestion和高流量的请求。另外有多个前端集群的好处是,将每个故障域缩小了。
为了保持各个集群中的缓存和存储一致,需要将过期的缓存删除。Facebook使用了以下手段:
- 在存储中的内容如果被修改了,在SQL语句中添加要删除的memcache字段,由在数据库机器上运行的mcsqueal守护进程定期提取字段并广播到每个前端集群删除;
- 1中的方法因为是all to all,不太高效,还可以进一步使得mcsqueal将要删除的memcache字段批量整理,并发送到前端集群的mcrouter中间件,由mcrouter中间件向在同一集群的缓存发送删除指令,这提升了18倍的删除效能;
- 网络服务器在修改存储数据之后,也删除在同一个集群的缓存服务器中的过期数据,来保证写入后读取一致性;
- 在3中,网络服务器仅仅删除在同一个集群的缓存服务器中的过期数据,而不是广播到所有集群,因为广播会导致一些问题。比如,广播删除相比起2中经过mcsqueal处理的批量删除,效率更低、成本更大。另外,一旦一个网络服务器广播出错,就要重启所有的缓存集群,将故障域加大了。而mcsqueal进行删除还有一个好处是,因为它依赖于可以找到的sql语句和binlog,可以在出错时进行回播。
在重启集群时,为了缩短冷启动(缓存命中率很低)时间,允许其从其它没有重启的集群中取到缓存,以减少对存储系统的压力。在这里有可能出现冷集群从热集群中拿到过期数据(一个用户在冷集群中更新了数据库的数据,而另一个读取冷集群数据的用户在热集群的缓存应该被删除之前,拿到了缓存的数据放到冷集群中)的情况。实际操作中,对于冷集群中的数据更新而造成的缓存删除操作,保留了2秒钟的操作时间,如果在这两秒钟之内,有用户从冷集群读取这个数据,向热集群读取的缓存没法加到冷集群的缓存中,导致冷集群需从数据库中重新读取数据。
多区域扩容(Across regions)
多区域扩容有着以下好处:
- 服务器接近用户终端,缩短网络通信时间;
- 增加地域容错性,某区域自然灾害不会对服务造成太大;
- 在某些地区架设服务器能提供更低的成本。
对于Facebook的架构来说,将服务器分布于某些区域,每个区域中有主或者只读数据库作为存储系统,同时有多个前端集群。
与之伴随而来的最大困难是如何保持数据一致性。下面举例说明,我们假定A区域为主库所在,B区域为从库所在。
由于主从数据库位于不同地区,有一定的复制延迟,如果一个客户从A区域进行写操作,而在B的从数据库收到写复制之前,就对B区域的缓存进行清除操作,并且这时有客户从B区域读取数据,那么会读取到数据库里的过期数据并使缓存也过期。幸而就如之前介绍,缓存删除是由数据库主机上的mcsqueal进行批量删除的,依赖于binlog,可以避免这个竞争条件。
如果一个客户从B区域进行写操作,而从数据库有很大的复制延迟(也就是说,缓存没有被清除,因为缓存要在从库复制完之后再进行删除),那么之后这个客户从B区域读的时候,会读到没有更新的缓存。这违反了”写入后读取一致性“的体验,对于一些客户来说是不可接受的。为了解决这个问题,Facebook用了一个”远程标记“的方法:在B区域发起的写操作,在B区域标记一个”远程标记“表明B区域的数据库/缓存是过期的,然后写操作会更新A区域的主库(将缓存键和之前做的远程标记放到sql语句中),然后在B区域将缓存键删除。当B区域从库收到复制流的时候,会读取之前做的远程标记并将之删除。那么当B区域在从库收到复制流之前,发起读操作的时候,如果没有远程标记这个操作,读到的是从数据库中的未更新数据,但是如果它检测到了远程标记的存在,那么就会到主库去读数据。
提升单机性能
服务器:2.67GHz(12核心和12个超线程)英特尔Xeon CPU,英特尔82574L千兆以太网控制器和12GB内存。每台服务器24个线程。
15个客户端,客户端和服务器位于同一机架上,并通过千兆以太网连接。
测试时间两分钟。
| 措施 | 性能变化 |
|---|---|
| 细颗粒度多线程锁 | 3x cache hit, 1.7x cache miss |
| 用UDP而不是TCP | 8%~10% |
| 批量查询(multiget)而不是single get | 10-key multiget shows 4x thoughput increase |
另外,memcache通过块分配器(slab allocator)来管理内存。对于流量突然增加的时候,可能会造成有些服务器中的内存不够,导致缓存命中率降低。Facebook通过自适应块分配器(adaptive slab allocator)定期调整块分配,找到在驱逐缓存项时比其它块分类中最近使用的条目的平均使用时间还要近20%的块分类(也就是说这个块分类驱逐的缓存特别新),那么会增加这个块分类的数量。选择驱逐缓存的时间而不是驱逐率作为标准,是因为驱逐率更受访问模式的影响。
为了减少系统升级时需要重新获取的数据和数据结构,将memcached的数据和数据结构放在System V共享内存区域,使得进程在重启时能从内存中直接读取数据。
总结
1、将缓存和储存系统分开,能更方便地扩张两个系统;
2、运维的工具与性能一样重要;
3、有状态的组件比无状态的组件复杂,因此将一些逻辑放在无状态的客户端会更好;
4、系统一定要能支持灰度发布与回滚;
5、简单至关重要。
Ref
- 原文
- https://engineering.fb.com/2014/09/15/web/introducing-mcrouter-a-memcached-protocol-router-for-scaling-memcached-deployments/
- https://www.youtube.com/watch?v=m4_7W4XzRgk
- https://www.youtube.com/watch?v=Myp8z0ybdzM