RocksDB 总述
SSD与HDD相比,具有高读写速度,写入周期有限等特征。rocksdb参考google的LevelDB发展而来,它能减少写放大从而增加写效率,减少物理磨损。它能为不同性质的服务所用,比如数据库、流处理、日志、索引、缓存等。
LSM树
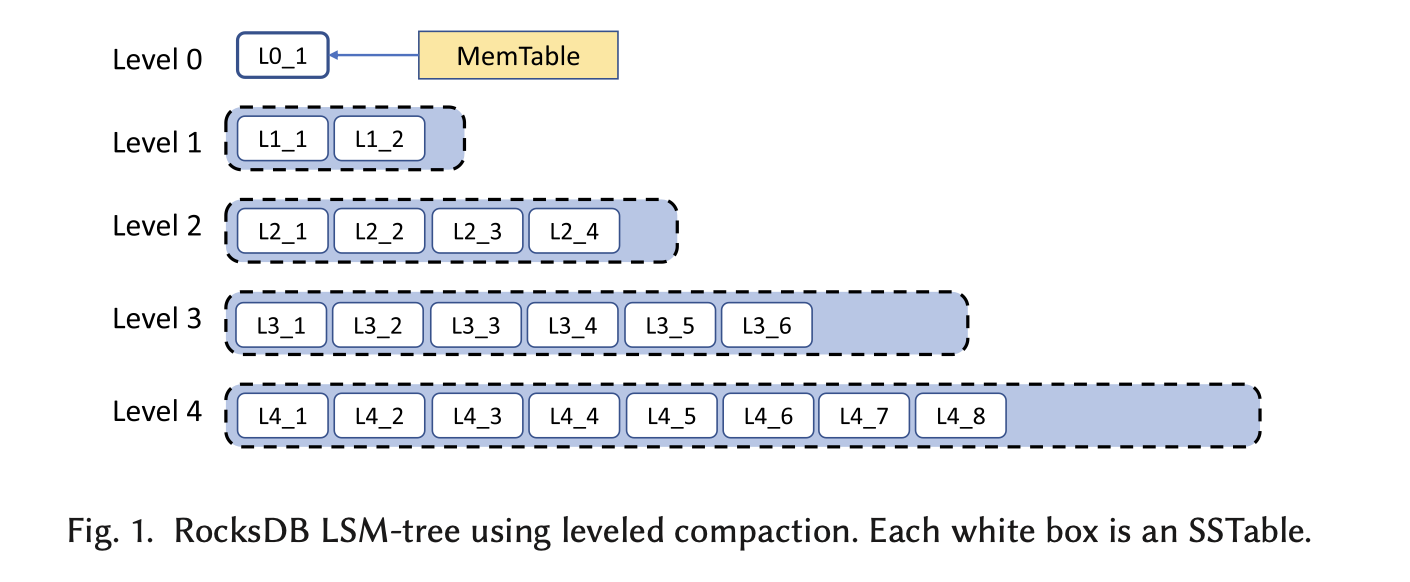
Rocksdb用了LSM树(Log-Structured Merge-tree,日志结构合并树),下面是对各个流程的简介:
-
写入流程:
-
MemTable:写入操作首先将数据写入内存中的一个结构,称为MemTable,同时写WAL到磁盘上。MemTable用了跳表(skiplist)的数据结构,使数据有序排列,并有O(log n)的读写复杂度。当MemTable达到一定大小后,它会被写入到磁盘,形成一个SSTable(Sorted String Table),同时已被写入磁盘的MemTable和相应WAL会被删除。
-
SSTable:SSTable是已排序的键值对集合,存储在磁盘上。每次MemTable转换成SSTable时,都会在LSM树的最上层(L0层)创建一个新的SSTable文件。SSTable文件生成后是不可改动的,它有索引块结构来进行二分法查找。
-
-
合并和压缩(Compaction):
-
随着时间的推移,磁盘上会积累多个SSTable。LSM树通过一个称为“合并和压缩”的过程来优化存储空间和查询效率。这个过程涉及将多个SSTable合并为一个,同时删除重复的或过时的键值对(除非有snapshot正在读,会保留)。在这个过程中,第X层的SSTable会与第X+1层的SSTable根据相同键值进行合并。
-
不同的压缩机制会影响读写性能。若压缩频率高,则查找SSTable更快,但写放大更多;若压缩频率低,则写放大较少,但查找更慢。
-
-
读取流程:
- 读取操作首先在MemTable中查找数据,如果未找到,再依次在每个层级的SSTable中查找。为了提高查找效率,通常会使用布隆过滤器(Bloom Filter)来快速确定数据是否存在于某个SSTable中。读取较多的SSTable会被缓存在内存中。
在MemTable中,键值对用跳表排序,可以重复。 在L0中,键值对在一个SST中是排序的,在同一层中不是排序的,键值可以重复。 L1至LMAX层,键值对在一个SST,以及在同一层中都是排序的。L1层开始,就已经进入了压缩的流程,相同键值只保存seqno最大的那一份(除非有snapshot在读,对一个键值需要保存多个seqno)。排序时先用key排序,再用seqno排序。
针对资源的优化
- 减少写放大是rocksdb初期利用LSM树最直接的目标。写放大指的是实际写入到存储介质上的数据量相对于原始要写入的数据量的比率增加,这种现象会导致存储设备的写入操作比实际应用层面的数据更新更频繁,进而影响存储设备的性能和寿命。写放大表现在两个层面,一个是SSD层面(1.1-3倍的放大率),另一个是软件层面(用LSM树是10-30倍的放大率,用B树因为random write, page split/merge, maintain tree balance等维护操作需要200-600倍的放大率)。尽管10-30倍的放大率比起B树已是进步,但依然有进步空间。比起level compaction,Tiered Compaction能使放大率下降到4-10倍,但同时也会降低读性能。
- 因为有许多应用的瓶颈不在于写放大,而在于空间利用,rocksdb增加了dynamic leveled compaction。它根据新旧数据层大小的比例来推测出有多少dead data(很有可能被update覆盖的数据)。数据显示,它与leveled compaction相比能减少12%的储存空间,在worst case scenario能减少77%的储存空间。
- 针对一些写入频率高、写入很多大型对象的应用,开发了BlobDB,将写入对象根据大小分开管理以减少写放大。
大型系统使用RocksDB要考虑的因素
- 资源管理,包括内存管理、压缩带宽、压缩线程、磁盘使用、文件删除速度等。对于同一性质的工作,不同实例之间共享同一线程池,能防止CPU和I/O过载。但同时也要注意没有分配到线程的实例可能会因此等待过久,而造成读/写放大,影响性能,甚至造成写停滞。
- 数据复制/备份。有两种数据复制创造新实例的方法:
- Logical Copy,将数据全部读取再导入到新实例中(select, dump),这时可能造成cache trashing的问题,因为在复制过程中可能使缓存因扫描操作中的临时或不那么重要的数据取代更频繁访问的数据。另外,在写入的实例中,bulk loading的使用能使写入直接到达Lmax一层,减少了在MemTable层以及压缩带来的负担。
- Physical Copy,直接复制SSTable等文件,这也是为什么RocksDB选择使用底层文件系统(更具有兼容性、灵活性),而不是直接使用块设备接口(block device interface)或SSD的Flash Translation Layer(FTL)。
- 在有数据冗余的情况下,提供WAL sync的不同选项,以进一步提高性能。
- 数据向后和向前兼容性。
关于数据损坏
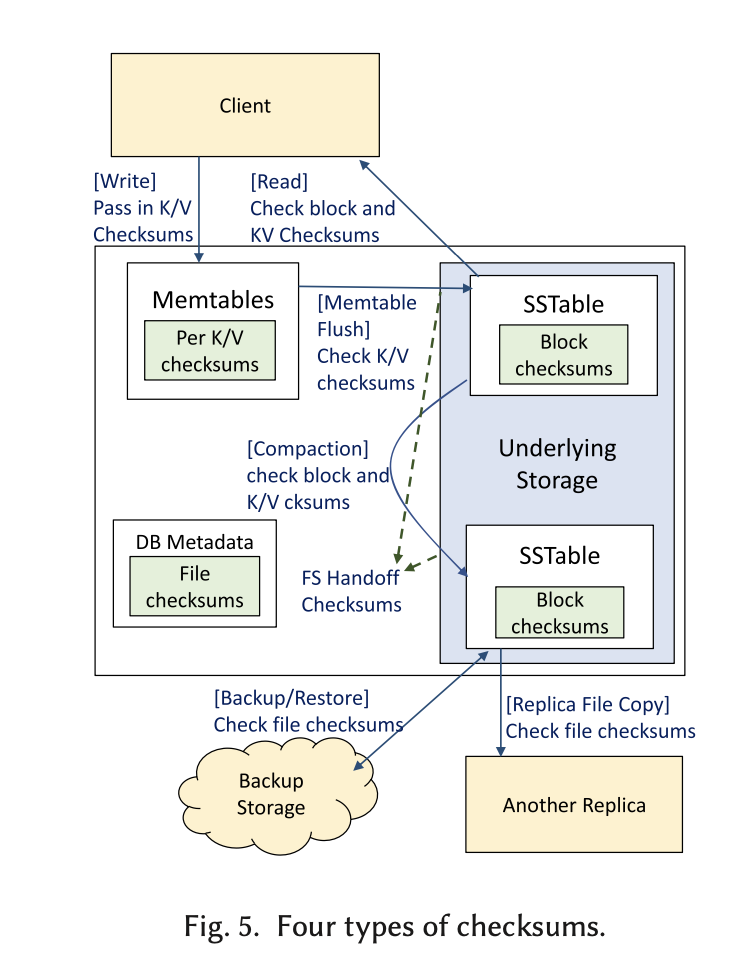
数据损坏可能发生在各个层面,比如软件操作层面(如复制、备份等)、CPU/内存、数据传输层面。通常,用RocksDB的系统都会有一些冗余备份,来替换那些数据损坏的实例。但是如果所有冗余都有数据损坏呢?我们需要更多的手段来尽早检测数据损坏。RocksDB采取的方法有:
- KV checksum。在文件层以上,主要保护MemTable和block cache的准确完整性。
- Block checksum。在文件层,每个SSTable block/WAL fragment有个checksum,在每次读的时候检查。
- SSTable checksum。在文件层,在每次传输的时候检查。
- Handoff checksum。针对保护WAL,在远程存储系统中可在write API接受一个ECC的参数来检查checksum。
针对不同客户需求的优化
- Compaction filter。在压缩时,用户可决定除压缩以外对KV键进行什么操作,如删除、更新等。在Facebook就用它(?)实现了TTL(time-to-live)功能,当每个KV键上有过期值的提示,在压缩时会删除那些过期的值。同理也可以在压缩时检查版本号,实现GC来支撑MVCC,或者收集信息等。它本质上利用了compaction这个LSM必然发生的在储存引擎上的功能,来代替应用层面需要进行的大型扫描操作,更快速、安全、便捷。它同时也带来了一些问题,比如如何保持快照读一致性引等。
- Merge operator。对于read-modify-write的操作来说,通常需要应用进行3步操作,merge operator能使其原子化成为一步操作。带来的问题是读键值时,需要一直读到Put record,增加了读的成本。
- 关于删除的优化:通过在键值上标记tombstone来表示键值可删除,但要注意必须保证SSTable最高(最旧)的那层已经没有该键值了。如果在Lmax-1有被标记成tombstone的键值,而在Lmax没有,此时把Lmax-1层的值删了,会导致数据不一致,因为会读到旧的值。在一些情况下,如果已有大量的tomestone标记,则range scan的时候需要跳过这些键值,很费时间。对此的优化方法有:1)根据tomestone所占比例设置compact频率;2)设置插件,在压缩过程中使SSTable中有tomestone标记的键值移到最后一层从而被删除;3)在tomestone太多时报告给应用层;4)使RockDB追踪一个键值在SSTable出现的最早时间,应用可设置参数来规定键值在多少时间内必须被压缩到最后一层。
- 关于内存管理,RocksDB用的是第三方内存分配器,来分配变量大小的内存块。它虽然在大多数场景中使用合理,但也会带来内存碎片化的问题,可以通过调整jemalloc的设定来优化,比如调整jemalloc中tcache的设置,将短期和长期对象分别用不同的jemalloc池来控制等。
对KV接口的优化
-
RocksDB有数据版本号的支持,但是这不能满足对于过去数据的读取(point-of-time read),而且每个实例的版本号是分别设立的,这就不能实现跨实例的一致性读取。RocksDB为此添加了User defined Timestamp,能在写入时在API增加一个timestamp的元数据,使sst中的数据成为:
1
2|user key|timestamp|seqno|type| |<-------internal key-------->| -
很多数据库(如MyRocks, CockroachDB, TiDB, Rocksandra等)在使用RocksDB时,使用了列存储,这使RocksDB有动机对这些应用进行更好的列原生支持。
Ref
- 原文:https://www.usenix.org/system/files/fast21-dong.pdf
- Skip List:https://www.youtube.com/watch?v=ol-FaNLXlR0&t=260s
- LSM Trees: https://www.youtube.com/watch?v=oUNjDHYFES8
- RocksDB简介:https://www.youtube.com/watch?v=jGCv4r8CJEI
- LSM compaction deep dive: https://www.alibabacloud.com/blog/an-in-depth-discussion-on-the-lsm-compaction-mechanism_596780